Nevím jak vám, ale nám se při vývoji často stává, že vývojáři některé věci přehlíží a to se nám negativně odráží na produktivitě a kvalitě výstupu. Člověk je tvor omylný, ale inteligentní a proto se snaží se vybavit takovými nástroji, které jeho nedokonalosti dokáží vyvážit. Na posledním hackathonu kolega
Michal Kolesnáč přišel s nápadem a prototypem rozšíření našeho
existujícího doplňku pro Google Chrome, které pomocí
HTML 5 notifikací upozorní vývojáře na potenciální problémy na prohlížené web stránce. Minulý týden jsme řešení dotáhli do konce a myslím, že stojí za to, abych se s Vámi o tento nápad podělil.
Na úvod se podívejte, jak nám výsledné řešení pomáhá v praxi:
[youtube=https://www.youtube.com/watch?v=dluseSIN3tU]
Princip fungování
Princip je relativně obecný a je určitě přenositelný i do vašeho vývojového ekosystému. O vývoji rozšíření pro Chrome toho už bylo
napsáno i v češtině docela dost a proto zde nepůjdu do úplných podrobností.
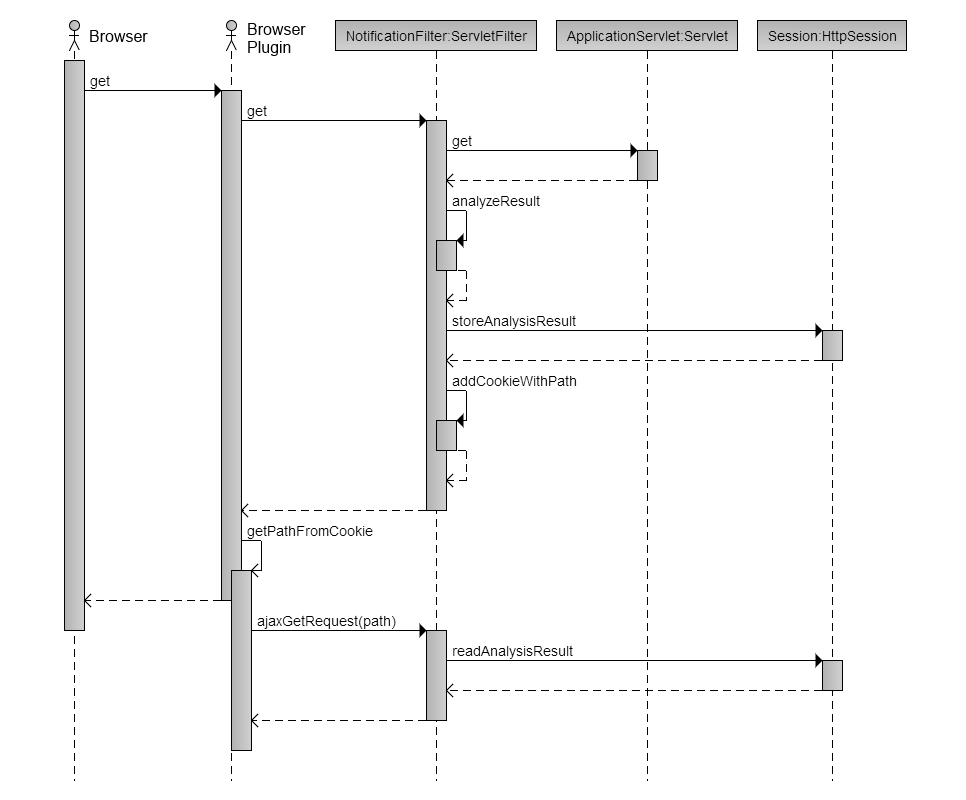
Celý princip je zachycen na následujícím sequence diagramu (btw. vytvořený v
http://www.ckwnc.com/ ... což je krásná služba pro generování sequence diagramů - jen nedoplňuje popisky k aktorům):
Jednoduše řečeno - každý požadavek na webovou aplikaci prochází servletovým filtrem, který při každém požadavku vygeneruje unikátní token a zapíše do hlaviček odpovědi cookie obsahující URL, na kterém bude v budoucnu odpovídat na požadavky pro zobrazení zpráv spojených s tímto requestem. Po ukončení zpracování HTTP požadavku filtr zanalyzuje aktuální stav aplikace a případně zapíše zprávy pro vývojáře ohledně věcí, kterým by měl věnovat pozornost.
Chrome plugin monitoruje změny cookies a pokud narazí na změnu v cookie se sledovaným názvem, vybere z ní URL, vytvoří XmlHttpRequest a AJAXem se dotáže serveru na seznam zpráv k zobrazení. Požadavek zachytí opět náš servletový filtr, podle unikátního tokenu si ze session vytáhne dříve vygenerovaný seznam zpráv. Nakonec vytvoří JSON zprávu s odpovědí, která obsahuje buď prázdné pole, nebo seznam notifikací s dodatečnými informacemi (např. důležitostí sdělení). JSON je pluginem rozparsován a uživateli jsou prezentovány zprávy jako HTML 5 notifikace. Je důležité si uvědomit, že najednou mohou být zobrazeny pouze 3 notifikace (omezení prohlížeče) a proto je potřeba ty zprávy koncipovat spíše jako odkazy někam dál. V našem případě otvírám po kliknutí na notifikaci
RamJet Inspektor, kde je k nalezení už konkrétní rozpad problému.
Cílem rozhodně není zahltit vývojáře informacemi - notifikace mají zobrazovat jen informace o důležitých problémech, které vyžadují pozornost a je riziko, že by je vývojář mohl přehlížet. Naopak pokud by je chtěl přehlížet, tak by mu měly notifikace jeho ignoranci alespoň znepříjemnit :).
V našem případě aktuálně monitorujeme tyto problémy:
- pomalá odezva stránky (více jak 1 vteřina na vrácení kompletního výstupu)
- pomalé SQL dotazy při zpracování požadavku (více jak 200ms na zpracování SQL příkazu)
- duplicitní SQL dotazy (špatné použití cachování)
- chyby při zpracování stránky (jak při akci, tak i v rámci renderingu) - obvykle by měly být vidět samy od sebe, ale někdy se skryjí ve <script> blocích nebo na stránce chybí komponenta pro výpis chybových hlášení
- chyby při aplikaci změn v konfiguraci (refresh Spring kontextů selhal) - jelikož se jede z poslední známé funkční konfigurace, vývojář často problém s reloadem nepostřehne a marně pátrá proč se aplikace nechová tak, jak by podle poslední konfigurace měla
- (zvažujeme) použití deprekovaných komponent a funkcí
- (plánujeme) zobrazení informace o nelokalizovaných textových popiscích na stránce
A také tyto významné informace v životním cyklu aplikace:
 Po 3 letech dělám větší refaktoring na našem direct mailingovém modulu a jako první jsem se rozhodl povýšit verze knihoven a zrefaktorovat JUnit testy, které jsou tam ještě psané ve stylu JDK 1.4.
Po 3 letech dělám větší refaktoring na našem direct mailingovém modulu a jako první jsem se rozhodl povýšit verze knihoven a zrefaktorovat JUnit testy, které jsou tam ještě psané ve stylu JDK 1.4.
V souvislosti s tím jsem samozřejmě přepracoval formu testů z dědičné hierarchie na anotace, které byly představeny poprvé ve Spring 3.X (pokud se nepletu). A tu jsem zjistil, že mám drobný problém - v původní verzi mého kódu jsem využíval dynamické kompozice Springového kontextu k tomu, abych stejné integrační testy pustil proti různým implementacím úložišť dat (paměť, MySQL databáze, Oracle databáze ...). V aktuální verzi Springu se ale v anotaci @ContextConfiguration uvádí statický výčet konfiguračních XML a to situaci komplikuje.

Tento víkend se v Pardubicích konal historicky první "pardubický" Google DevFest a bylo by hříchem nevydat se na tak zajímavou akci zvlášť, když probíhá jen pár stovek metrů od mého domu. Na programu byli přitom samí zajímaví řečníci - Michal Špaček, Daniel Steigerwald, Pavel Lahoda, googleři Danut Echanoiu a Margarita Manterola a další.
Pokud vás zajímá, jak vše vypadalo okem diváka, připravil jsem pro vás tuto reportáž.
OAuth 2 (Danut Echanoiu)
První přednáška Danuta Echanoiu byla na již trošku ohrané téma OAuth autentizačního a autorizačního protokolu. Ačkoliv jsem již byl asi na dvou přednáškách o OAuth - tato mi přišla mimořádně dobrá a to především kvůli tomu, že veškeré technikálie byly vysvětleny velmi jednoduše a lidsky.
 Nedávno jsem jedním svým twítem vyvolal menší diskusi ohledně toho, co nám dovoluje komponentový framework oproti tomu, čeho bychom byli schopni dosáhnout s jednoduchým MVC rámcem. Bohužel twitter mi nedává takovou možnost vyjádřit se a tak jsem chtěl důvody a výhody, které vidím v komponentách na frontendu, popsat trošku obšírněji v tomto článku.
Nedávno jsem jedním svým twítem vyvolal menší diskusi ohledně toho, co nám dovoluje komponentový framework oproti tomu, čeho bychom byli schopni dosáhnout s jednoduchým MVC rámcem. Bohužel twitter mi nedává takovou možnost vyjádřit se a tak jsem chtěl důvody a výhody, které vidím v komponentách na frontendu, popsat trošku obšírněji v tomto článku.
Komponentový model na webové vrstvě přináší oproti MVC se "standardním" šablonovým systémem možnost elegantní znovupoužitelnosti částí, které se znovu použít dají. Pro mě jako vyznavače DRY je toto jedna z VELKÝCH výhod. Namítnete, že znovupoužitelnosti se přeci dá dosáhnout i v běžném šablonovacím systému - co třeba JSP tagy nebo Freemarkerová makra? Touhle cestou jsem si prošel a výsledek byl vždycky kostrbatý - obvykle se vám podaří znovupoužít buď vykreslovací šablonu nebo aplikační logiku, ale nikdy ne rozumně obojí.
 Jestli ano, tak by mne velmi zajímalo, jak to děláte. My jsme totiž ještě donedávna žádnou jistotu neměli - vše záleželo na poctivosti a důslednosti programátorů. Jenže v Javě není tahle záležitost vůbec jednoduchá a tak vám může díky nějaké referenci hluboko ve stromu objektů uniknout, že to, co ukládáte do session, má vazbu na objekt, který serializovatelný není. Výsledkem je ztráta session při restartech aplikačního serveru nebo zamezení možnosti session replikovat mezi nody clusteru.
Jestli ano, tak by mne velmi zajímalo, jak to děláte. My jsme totiž ještě donedávna žádnou jistotu neměli - vše záleželo na poctivosti a důslednosti programátorů. Jenže v Javě není tahle záležitost vůbec jednoduchá a tak vám může díky nějaké referenci hluboko ve stromu objektů uniknout, že to, co ukládáte do session, má vazbu na objekt, který serializovatelný není. Výsledkem je ztráta session při restartech aplikačního serveru nebo zamezení možnosti session replikovat mezi nody clusteru.
 Škálování databází je velké téma a já rozhodně nejsem takový odborník, abych tady rozebíral kdovíjaké detaily. Zcela jistě znáte termíny jako je sharding, o kterém psal Dagi už před 5 lety, popřípadě znáte termín partitioning, který nám nabízejí některé DB stroje "zadarmo" a jiné "za peníze". Alternativním způsobem horizontálního škálování je škálování pomocí sady replik pro čtení, o kterém lze uvažovat v případě, že máte aplikaci, které řádově méně zapisuje do databáze než z ní čte. Konkrétně se jedná o to, že máte několik databázových strojů v režimu MASTER-SLAVE(S), který se často nasazuje už jen z důvodu hot-backupu (tj. v případě výpadku master databáze je možné velmi rychle z repliky učinit nový master a pokračovat v běhu aplikace).
Škálování databází je velké téma a já rozhodně nejsem takový odborník, abych tady rozebíral kdovíjaké detaily. Zcela jistě znáte termíny jako je sharding, o kterém psal Dagi už před 5 lety, popřípadě znáte termín partitioning, který nám nabízejí některé DB stroje "zadarmo" a jiné "za peníze". Alternativním způsobem horizontálního škálování je škálování pomocí sady replik pro čtení, o kterém lze uvažovat v případě, že máte aplikaci, které řádově méně zapisuje do databáze než z ní čte. Konkrétně se jedná o to, že máte několik databázových strojů v režimu MASTER-SLAVE(S), který se často nasazuje už jen z důvodu hot-backupu (tj. v případě výpadku master databáze je možné velmi rychle z repliky učinit nový master a pokračovat v běhu aplikace).
 Do you use Commons File Upload library in your application? Do you use DiskFileItemFactory for storing big files to a temporary disk storage? Do you use FileCleaningTracker to get rid of unused temporary files as it is recommended in documentation?
Do you use Commons File Upload library in your application? Do you use DiskFileItemFactory for storing big files to a temporary disk storage? Do you use FileCleaningTracker to get rid of unused temporary files as it is recommended in documentation?
If so you probably have a memory leak in your application you don't know about.
Stored files are meant to be cleared when there is no reference to the FileItem instance created by this library. Or at least this is stated in the documentation:
 Pod ladícím nástrojem si většina Java vývojářů představí Java debugger. O něm však v tomto článku řeč nebude. Chtěl bych vám tu představit náš přístup k doprovodným nástrojům pro tvorbu webové vrstvy a podívat se kolem sebe, jestli jsme v tomto ohledu originální či nikoliv.
Pod ladícím nástrojem si většina Java vývojářů představí Java debugger. O něm však v tomto článku řeč nebude. Chtěl bych vám tu představit náš přístup k doprovodným nástrojům pro tvorbu webové vrstvy a podívat se kolem sebe, jestli jsme v tomto ohledu originální či nikoliv.
Nápad vytvořit specifické nástroje se znalostí interních mechanismů použitého frameworku je již poměrně starý. V českém PHP frameworku Nette vznikla tzv. Laděnka někdy na začátku roku 2008 (vycházím ze zmínky na blogu Davida Grudla).
 Na tento poklad narazil kolega Jakub Liška, když si sám chtěl napsat něco podobného. Pokud používáte pro automatické testy podporu Springu a na vytváření mocků Mockito, máte řadu možností jak vytvářet mock objekty. Jednu z nich, která se mi zdála poměrně jednoduchá jsem popisoval v dřívějším článku Jak se zbavit nepříjemných závislostí v testech, nicméně tento přístup dotáhl Jakub Janczak o kus dál (jo na světě jsou milóny lidí chytřejších jak já :) ).
Na tento poklad narazil kolega Jakub Liška, když si sám chtěl napsat něco podobného. Pokud používáte pro automatické testy podporu Springu a na vytváření mocků Mockito, máte řadu možností jak vytvářet mock objekty. Jednu z nich, která se mi zdála poměrně jednoduchá jsem popisoval v dřívějším článku Jak se zbavit nepříjemných závislostí v testech, nicméně tento přístup dotáhl Jakub Janczak o kus dál (jo na světě jsou milóny lidí chytřejších jak já :) ).
 Many of complex applications put on top of their complexity access control logic for securing data and to limit access to certain functions. No matter if you have fully configurable ACL settings based on rights or role based access you'd probably want to test this part of application too. In order to have proper test coverage you should make it easy for you and your colleagues to test this. I have no doubts that if you ever needed to test this you already have some kind of such test support, but this article describes what kind of it I've created for myself. It might be interesting for you to compare it with your solution or inspire you to create one if you haven't done it already.
Many of complex applications put on top of their complexity access control logic for securing data and to limit access to certain functions. No matter if you have fully configurable ACL settings based on rights or role based access you'd probably want to test this part of application too. In order to have proper test coverage you should make it easy for you and your colleagues to test this. I have no doubts that if you ever needed to test this you already have some kind of such test support, but this article describes what kind of it I've created for myself. It might be interesting for you to compare it with your solution or inspire you to create one if you haven't done it already.
 Nespoléhejte se na to, že, tak jako Java samotná, budou i základní knihovny a nástroje respektovat důležitost zpětné kompatibility. Například v případě Tomcatu se nám už několikrát stalo, že při upgradu na verzi, kde se mění pouze číslo patche, se kompletně rozpadla funkčnost aplikace. Poprvé to bylo myslím, když v patchi vyupgradovali na novější specku JSP a teď nám zase přihodili bombičku v podobě změny obsahu httpServletRequest.getPathInfo(), která nově vrací i tzv. path parametry.
Nespoléhejte se na to, že, tak jako Java samotná, budou i základní knihovny a nástroje respektovat důležitost zpětné kompatibility. Například v případě Tomcatu se nám už několikrát stalo, že při upgradu na verzi, kde se mění pouze číslo patche, se kompletně rozpadla funkčnost aplikace. Poprvé to bylo myslím, když v patchi vyupgradovali na novější specku JSP a teď nám zase přihodili bombičku v podobě změny obsahu httpServletRequest.getPathInfo(), která nově vrací i tzv. path parametry.
 Spring security is really powerful library in its current version and I like it much. You can secure your application on method level several years now (this feature was introduced by Spring Security 2 in 4/2008) but we've upgraded from old Acegi Security only recently. When using method access control in larger scale I started to think about security rules encapsulation into standalone annotation definitions. It's something you can live without but in my opinion it could help readibility and maintainability of the code. Let's present some options we have now ...
Spring security is really powerful library in its current version and I like it much. You can secure your application on method level several years now (this feature was introduced by Spring Security 2 in 4/2008) but we've upgraded from old Acegi Security only recently. When using method access control in larger scale I started to think about security rules encapsulation into standalone annotation definitions. It's something you can live without but in my opinion it could help readibility and maintainability of the code. Let's present some options we have now ...

 Před týdnem jsem byl pozváni na přednášku Juergena Höellera - jednoho z autorů Spring Frameworku, který již léta dohlíží na směrování tohoto velmi populárního aplikačního rámce našich Java aplikací. Akci organizovala společnost Morosystems v Brně a tímto jim děkujeme za pozvání.
Před týdnem jsem byl pozváni na přednášku Juergena Höellera - jednoho z autorů Spring Frameworku, který již léta dohlíží na směrování tohoto velmi populárního aplikačního rámce našich Java aplikací. Akci organizovala společnost Morosystems v Brně a tímto jim děkujeme za pozvání. Every improvement of your development process that is performed on daily basis is worth considering and implementing. Even little things can save days in budgets if you multiply them by the count of team members and the number of operation occurrences in the year. How do you look up for classes or JSP/FreeMarker/whatever templates when you run at error in them during development or testing? In development mode you might have your logging output open in IntelliJ Idea and click through exception stacktraces if any happens to be printed there. But there are cases when it's not possible - for example errors in templates won't navigate you to the source template, logs in test / preprod environment can't be easily consumed by your IDE etc.
Every improvement of your development process that is performed on daily basis is worth considering and implementing. Even little things can save days in budgets if you multiply them by the count of team members and the number of operation occurrences in the year. How do you look up for classes or JSP/FreeMarker/whatever templates when you run at error in them during development or testing? In development mode you might have your logging output open in IntelliJ Idea and click through exception stacktraces if any happens to be printed there. But there are cases when it's not possible - for example errors in templates won't navigate you to the source template, logs in test / preprod environment can't be easily consumed by your IDE etc.

 Je zajímavé, že tak základní věc, jako serializace objektů do binárního streamu je v Javě implementovaná neoptimálně - a to jak z hlediska velikosti výsledné binární podoby, tak i rychlosti s jakou je vytvořena. Míst, kde se serializace objektů hodí je celá řada, a proto je určitě v zájmu každého kvalitního vývojáře zamyslet se, jestli to nejde dělat líp.
Je zajímavé, že tak základní věc, jako serializace objektů do binárního streamu je v Javě implementovaná neoptimálně - a to jak z hlediska velikosti výsledné binární podoby, tak i rychlosti s jakou je vytvořena. Míst, kde se serializace objektů hodí je celá řada, a proto je určitě v zájmu každého kvalitního vývojáře zamyslet se, jestli to nejde dělat líp. There has been a lot of fuss around this issue and it seems there are already fixes in place. But in certain use-cases problems persist even if you apply fix mentioned in
There has been a lot of fuss around this issue and it seems there are already fixes in place. But in certain use-cases problems persist even if you apply fix mentioned in